
How Microsoft Power Platform is helping to modernize and enable...
In this webinar, our experts showcase a variety of demo use cases of how different components of the...
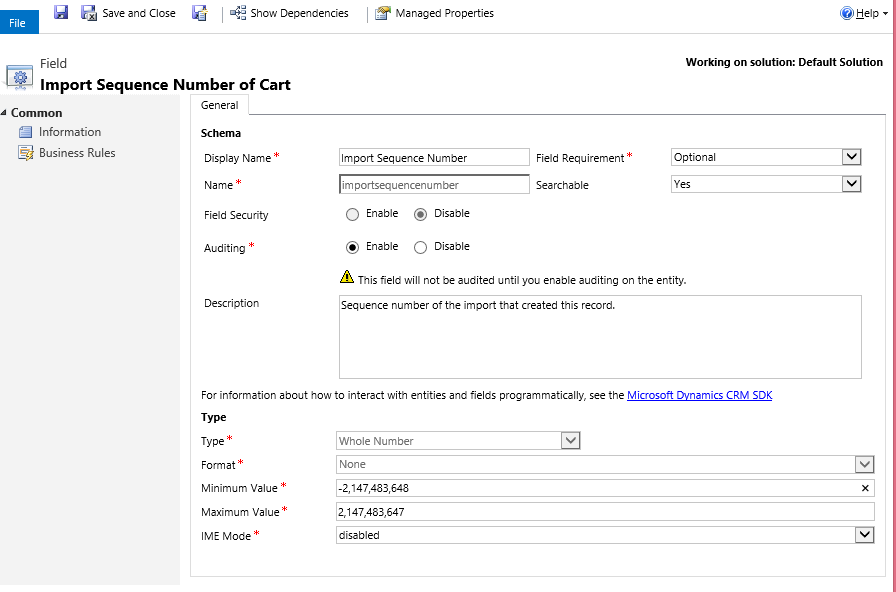
Most entities in Microsoft Dynamics CRM come with an out-of-the-box field called Import Sequence Number. This field is ignored most of the time as it is not shown in the form by default, but this is a very handy field for data migration.
The import sequence number is a whole number field. The range can be customized if needed. The basic idea behind this field is to store the sequence number (ID) of the source record during data import to CRM. If this field is mapped during migration package/script design, it provides a one-to-one link between source row and destination CRM record.
With bulk operations, we can send a batch of records to CRM at once and let it handle on its own. Bulk operations (as opposed to row-by-row operations) make it more difficult to handle failed rows as operation happens in bulk. If you do use bulk operations, you’ll need to design some alternative ways to handle the failed rows. This also applies to updating source records after they are migrated.
If you have on-premise or partner-hosted CRM and with access to a staging SQL database, you can make the best use of the import sequence number during data migration. It is highly recommended practice (if applicable) to stage the source data before loading to CRM.
There are a few advantages of this approach:
It’s good practice to design the staging tables with an integer identity ID column and make it a primary key so it will create a unique clustered index by default. When designing the migration script/package, map this ID field to the importsequencenumber field on CRM entity. This will create a one-to-one link between source row and CRM record. This comes very handy when there are any issues and records fail for some reason.
There is another good use of the ID field. It is usually a true statement that when multiple threads (packages) are run in parallel, there is a boost in migration performance. The ID field can be used to group records into different buckets so the individual package processes the records from its assigned bucket. The source query would look something similar to this for package #1:
Select * from Staging_Payment p with(nolock) where UpdateFlag=1 and ID<=1000000
And looks like this for package#2:
Select * from Staging_Payment p with(nolock) where UpdateFlag=1 and ID>1000000 and ID<=2000000
And so on.
At this point, you can kick off the bulk operation…don’t worry if records fail. Update the staging table with CRM record GUID and set the UpdateFlag to 0. (UpdateFlag=0 means that the records are already processed so it will not be picked up again by migration package.)
Here is sample code to update the source using importsequencenumber and ID:
UPDATE p SET
p.CRM_ID=b.po_paymentid
,p.UpdateFlag=0
FROM CRM_MSCRM..po_paymentBase b with(nolock)
JOIN Staging_Payment p with(nolock)
ON b.ImportSequenceNumber=p.ID
WHERE p.CRM_ID IS NULL
AND UpdateFlag=1;
Once the update source completes, rerun the package/script again to process the failed rows, i.e. the rows with ID in staging that is not in the CRM Import Sequence Number. Update source is very important for avoiding duplicate record creation in CRM if the migration packages are run multiple times.
If you use Scribe for migration, the pre- and post-processing feature can be used to automate this update source process.
Create a SQL script file with the above update script and save it in the same folder as the migration package.
Browse this file to run BEFORE and AFTER the job runs as below:
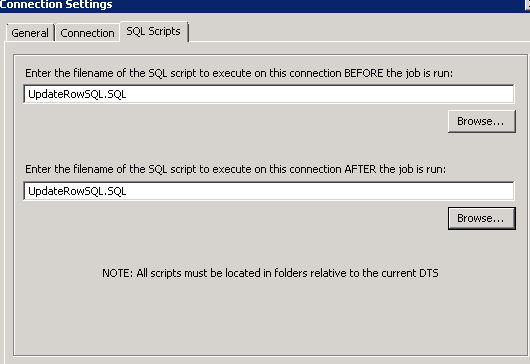
If SSIS is used for migration, then the above update script can be used in ExecuteSQL tasks before and after the Script component or Script Task whichever is used for calling CRM web service.
These are some of the little tips/tricks that can save you a lot of time during data migration time especially for large sets of data (in millions). You can read plenty more on migrating data in CRM on our blog!
Happy CRM’ing!






